{kind=link}
Voice AI has a dirty secret: most of it was never designed for conversation. The dominant paradigm — feed text in, get audio out — traces its lineage to audiobook narration and voiceover production, where the model never hears the person on the other end. That’s fine when you’re generating a podcast intro. It’s not fine when a frustrated user is trying to get support from an AI agent at 11pm.
Inworld AI is calling that out directly with the launch of Realtime TTS-2, a new voice model released as a research preview via its Inworld API and Inworld Realtime API. The model hears the full audio of the exchange, picks up the user’s tone, pacing and emotional state, then takes voice direction in plain English the way developers prompt an LLM.
What’s Actually Different Here
The meaningful architectural distinction with TTS-2 is that it operates as a closed-loop system. The model takes the actual audio of the prior turns of the exchange as input, not just a transcript — it hears how the user actually sounded. That’s a non-trivial difference. A transcript of “okay, fine” gives you the words. The audio of “okay, fine” tells you whether the person is relieved, resigned, or sarcastic. TTS-2 is designed to use that signal.
The same line lands differently after a joke than after bad news, and the model knows the difference because it heard the prior turn. Tone, pacing, and emotional state carry forward automatically. Practically speaking, audio context flows across turns inside a Realtime session without developers needing to pass explicit prior_audio fields or build additional plumbing.
Four Capabilities, One Model
Inworld team is shipping TTS-2 with four key features, positioning the combination and not any individual piece, as the differentiation.
The Conversational Layer Underneath
Beyond the four key features, it calls out a set of behaviors that push speech further into what it describes as “person paying attention” territory. The most technically interesting is disfluencies: the model generates natural uh and um, self-corrections, mid-noun-phrase pauses, and trailing thoughts that signal warmth and recall rather than malfunction. Critically, different speaker profiles cluster fillers differently, and the model follows the rhythm — filler-as-energy sounds different from filler-as-hesitation. Voice cloning is also supported via a two-step API: upload a reference sample (5–15 seconds, clean, single speaker) to /voices/v1/voices:clone, get a voice ID, and use it like any other voice.
Where It Fits in the Stack
TTS-2 is one layer in Inworld’s broader Realtime API pipeline. The full stack includes Realtime STT, which transcribes and profiles the speaker in one pass — capturing age, accent, pitch, vocal style, emotional tone, and pacing as structured signals on the same connection. A Realtime Router that routes across 200+ models, selecting the appropriate model and tools based on the user’s state and conversation context. And TTS-2 at the output layer. The pipeline runs over a single persistent WebSocket connection, with sub-200ms median time-to-first-audio for the TTS layer.
The Broader Context
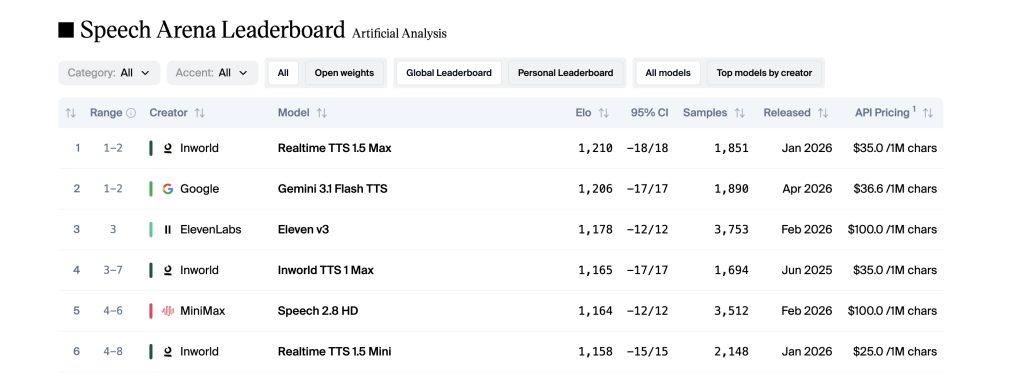
Realtime TTS 1.5 already ranks #1 on the Artificial Analysis Speech Arena (as of May 5, 2026), ahead of Google (#2) and ElevenLabs (#3). The launch of TTS-2 signals that Inworld considers raw audio quality a solved problem — and is now competing on the behavioral layer: context-awareness, steerability, and identity consistency across languages.
Check out the Docs and Technical details. Also, feel free to follow us on Twitter and don’t forget to join our 130k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us
The post Inworld AI Launches Realtime TTS-2: A Closed-Loop Voice Model That Adapts to How You Actually Talk appeared first on MarkTechPost.